


三网全程 CN2 GIA 专线直达,平均延时30+ms免备案





企业每年投入巨额资金进行营销活动,但如何准确评估这些投入的真实回报却是一个长期存在的挑战。
传统的营销评估方法往往存在严重缺陷——简单的"活动前后对比"忽略了自然增长趋势,"参与用户分析"则受到选择偏差的严重影响。
想象一下这样的场景:某电商平台开展了一次大规模会员促销活动,活动后销售额显著提升。表面看来活动非常成功,但这是否真的是活动带来的效果?可能同时存在季节性因素、竞争对手活动、宏观经济变化等混杂因素。如果没有科学的评估方法,企业可能会基于错误结论做出下一步决策,导致资源错配。
某大型电商平台"优购网"在2023年双十一期间开展了一次大规模会员专享促销活动。活动针对平台的金牌会员推出专项折扣、专属优惠券和优先配送服务。活动持续30天,覆盖平台约500万金牌会员,营销投入总计约2000万元。
活动结束后,初步数据显示:
然而,这些表面数字背后存在严重的选择偏差和混杂因素:
|
挑战类型 |
具体表现 |
潜在影响 |
|---|---|---|
|
选择偏差 |
金牌会员自选择成为会员,本身消费能力更强 |
高估活动效果 |
|
季节性因素 |
双十一期间整体消费水平提升 |
混淆活动效果 |
|
外部竞争 |
竞争对手活动影响用户行为 |
难以隔离净效果 |
|
长期效应 |
活动可能影响用户长期价值 |
短期分析不完整 |
基于业务需求,我们定义清晰的评估目标:
主要目标:量化会员促销活动的净增量收益(扣除自然增长和选择偏差)
具体评估指标:
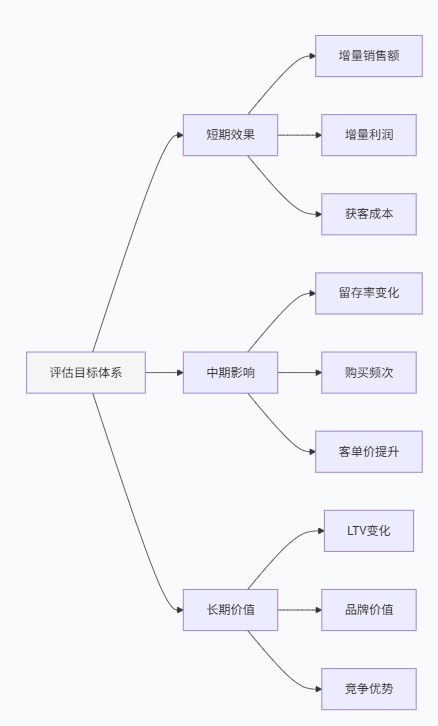
为了应对评估挑战,我们采用多方法验证的策略:
实验设计:由于业务限制无法进行完全随机实验,但可以利用准实验设计
数据策略:整合多源数据,构建合适的对照组
分析方法:结合双重差分(DID)、倾向得分匹配(PSM)等方法
现在我们已经明确了业务问题和评估框架,接下来需要收集和准备数据来支持分析。
为了全面评估营销活动效果,我们整合了多个数据源:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime, timedelta
import warnings
warnings.filterwarnings('ignore')
# 设置随机种子保证可重现性
np.random.seed(42)
# 生成模拟数据集(模拟真实业务数据)
def generate_marketing_data(n_users=100000, start_date='2023-09-01', end_date='2023-12-31'):
"""生成模拟的营销活动数据"""
# 日期范围
date_range = pd.date_range(start=start_date, end=end_date)
pre_period = [d for d in date_range if d < pd.Timestamp('2023-11-01')]
campaign_period = [d for d in date_range if d >= pd.Timestamp('2023-11-01') and d <= pd.Timestamp('2023-11-30')]
post_period = [d for d in date_range if d > pd.Timestamp('2023-11-30')]
# 用户基础特征
users = []
for i in range(n_users):
user = {
'user_id': i,
'age': max(18, min(70, int(np.random.normal(35, 10)))),
'income': max(2000, np.random.lognormal(10.2, 0.3)),
'city_tier': np.random.choice([1, 2, 3], p=[0.2, 0.5, 0.3]),
'signup_date': pd.Timestamp('2023-01-01') + timedelta(days=np.random.randint(0, 300)),
'is_gold_member': np.random.choice([0, 1], p=[0.7, 0.3]) # 30%是金牌会员
}
# 会员等级与用户价值相关
if user['is_gold_member'] == 1:
user['income'] = user['income'] * 1.5 # 会员收入更高
user['age'] = max(25, user['age']) # 会员年龄偏大
users.append(user)
user_df = pd.DataFrame(users)
# 生成用户行为数据
behavior_data = []
for user in users:
user_id = user['user_id']
is_gold = user['is_gold_member']
# 基础购买概率(会员更高)
base_purchase_prob = 0.1 if is_gold == 0 else 0.2
for date in date_range:
# 季节性效应:双十一期间购买概率提升
seasonal_effect = 1.0
if date >= pd.Timestamp('2023-11-01') and date <= pd.Timestamp('2023-11-30'):
seasonal_effect = 2.0 # 双十一期间整体购买概率翻倍
# 活动效应:仅对会员在活动期间有效
campaign_effect = 1.0
if is_gold == 1 and date in campaign_period:
campaign_effect = 1.5 # 活动额外提升50%
# 购买概率
purchase_prob = base_purchase_prob * seasonal_effect * campaign_effect
purchase_prob = min(purchase_prob, 0.8) # 设置上限
# 生成购买行为
has_purchase = np.random.binomial(1, purchase_prob)
if has_purchase:
# 购买金额(会员客单价更高)
base_amount = np.random.lognormal(5.5, 0.8) if is_gold == 0 else np.random.lognormal(6.0, 0.7)
# 活动期间金额提升
if date in campaign_period:
base_amount = base_amount * 1.2
amount = max(10, base_amount) # 最小金额10元
behavior_data.append({
'user_id': user_id,
'date': date,
'is_gold_member': is_gold,
'purchase_amount': amount,
'has_purchase': 1,
'period': 'pre' if date in pre_period else
'campaign' if date in campaign_period else 'post'
})
else:
behavior_data.append({
'user_id': user_id,
'date': date,
'is_gold_member': is_gold,
'purchase_amount': 0,
'has_purchase': 0,
'period': 'pre' if date in pre_period else
'campaign' if date in campaign_period else 'post'
})
behavior_df = pd.DataFrame(behavior_data)
# 合并用户特征和行为数据
final_df = behavior_df.merge(user_df, on='user_id')
return final_df, user_df
# 生成数据
print("开始生成模拟数据...")
marketing_data, user_info = generate_marketing_data(n_users=50000)
print(f"数据生成完成,总记录数: {len(marketing_data)}")
print(f"用户数: {marketing_data['user_id'].nunique()}")
print(f"数据时间范围: {marketing_data['date'].min()} 到 {marketing_data['date'].max()}")# 数据质量检查
def data_quality_check(df):
"""全面数据质量检查"""
quality_report = {}
# 基本统计
quality_report['total_records'] = len(df)
quality_report['unique_users'] = df['user_id'].nunique()
quality_report['date_range'] = f"{df['date'].min()} 到 {df['date'].max()}"
# 缺失值检查
missing_data = df.isnull().sum()
quality_report['missing_values'] = missing_data[missing_data > 0].to_dict()
# 异常值检测
purchase_amounts = df[df['purchase_amount'] > 0]['purchase_amount']
Q1 = purchase_amounts.quantile(0.25)
Q3 = purchase_amounts.quantile(0.75)
IQR = Q3 - Q1
outliers = purchase_amounts[(purchase_amounts < (Q1 - 1.5 * IQR)) |
(purchase_amounts > (Q3 + 1.5 * IQR))]
quality_report['outlier_count'] = len(outliers)
quality_report['outlier_ratio'] = len(outliers) / len(purchase_amounts)
# 数据一致性检查
gold_member_consistency = df.groupby('user_id')['is_gold_member'].nunique()
quality_report['inconsistent_gold_status'] = len(gold_member_consistency[gold_member_consistency > 1])
return quality_report
# 执行数据质量检查
quality_report = data_quality_check(marketing_data)
print("数据质量报告:")
for key, value in quality_report.items():
print(f"{key}: {value}")
# 数据清洗(处理异常值)
def clean_data(df, outlier_threshold=0.02):
"""数据清洗函数"""
# 复制数据避免修改原数据
cleaned_df = df.copy()
# 处理购买金额异常值(Winsorize方法)
purchase_amounts = cleaned_df[cleaned_df['purchase_amount'] > 0]['purchase_amount']
lower_bound = purchase_amounts.quantile(outlier_threshold)
upper_bound = purchase_amounts.quantile(1 - outlier_threshold)
cleaned_df['purchase_amount_clean'] = cleaned_df['purchase_amount'].clip(
lower=lower_bound, upper=upper_bound)
# 确保会员状态一致性
user_gold_status = cleaned_df.groupby('user_id')['is_gold_member'].first()
cleaned_df = cleaned_df.drop('is_gold_member', axis=1)
cleaned_df = cleaned_df.merge(user_gold_status.reset_index(), on='user_id')
print(f"异常值处理: 将{len(cleaned_df[cleaned_df['purchase_amount'] != cleaned_df['purchase_amount_clean']])}条记录的金额进行缩尾处理")
return cleaned_df
# 执行数据清洗
marketing_clean = clean_data(marketing_data)# 探索性数据分析
def exploratory_analysis(df, user_info):
"""全面的探索性分析"""
# 1. 用户特征分布
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# 会员分布
member_dist = df.groupby('user_id')['is_gold_member'].first().value_counts()
axes[0, 0].pie(member_dist.values, labels=['普通会员', '金牌会员'], autopct='%1.1f%%')
axes[0, 0].set_title('会员类型分布')
# 年龄分布
user_ages = user_info.groupby('user_id')['age'].first()
axes[0, 1].hist(user_ages, bins=20, alpha=0.7, edgecolor='black')
axes[0, 1].set_xlabel('年龄')
axes[0, 1].set_ylabel('用户数')
axes[0, 1].set_title('用户年龄分布')
# 收入分布
user_income = user_info.groupby('user_id')['income'].first()
axes[0, 2].hist(user_income, bins=30, alpha=0.7, edgecolor='black')
axes[0, 2].set_xlabel('收入')
axes[0, 2].set_ylabel('用户数')
axes[0, 2].set_title('用户收入分布')
# 2. 购买行为时间趋势
daily_stats = df.groupby('date').agg({
'purchase_amount_clean': 'sum',
'has_purchase': 'sum',
'user_id': 'nunique'
}).reset_index()
daily_stats['avg_spend'] = daily_stats['purchase_amount_clean'] / daily_stats['has_purchase']
daily_stats['purchase_rate'] = daily_stats['has_purchase'] / daily_stats['user_id']
axes[1, 0].plot(daily_stats['date'], daily_stats['purchase_amount_clean'])
axes[1, 0].axvline(x=pd.Timestamp('2023-11-01'), color='red', linestyle='--', label='活动开始')
axes[1, 0].axvline(x=pd.Timestamp('2023-11-30'), color='red', linestyle='--', label='活动结束')
axes[1, 0].set_xlabel('日期')
axes[1, 0].set_ylabel('日销售额')
axes[1, 0].set_title('日销售额趋势')
axes[1, 0].legend()
axes[1, 0].tick_params(axis='x', rotation=45)
# 3. 会员vs非会员对比
member_daily = df.groupby(['date', 'is_gold_member']).agg({
'purchase_amount_clean': 'sum',
'has_purchase': 'sum'
}).reset_index()
gold_daily = member_daily[member_daily['is_gold_member'] == 1]
regular_daily = member_daily[member_daily['is_gold_member'] == 0]
axes[1, 1].plot(gold_daily['date'], gold_daily['purchase_amount_clean'], label='金牌会员')
axes[1, 1].plot(regular_daily['date'], regular_daily['purchase_amount_clean'], label='普通会员')
axes[1, 1].axvline(x=pd.Timestamp('2023-11-01'), color='red', linestyle='--')
axes[1, 1].axvline(x=pd.Timestamp('2023-11-30'), color='red', linestyle='--')
axes[1, 1].set_xlabel('日期')
axes[1, 1].set_ylabel('日销售额')
axes[1, 1].set_title('会员类型销售额对比')
axes[1, 1].legend()
axes[1, 1].tick_params(axis='x', rotation=45)
# 4. 购买率对比
purchase_rates = df.groupby(['period', 'is_gold_member']).agg({
'has_purchase': 'mean',
'purchase_amount_clean': 'mean'
}).reset_index()
x = np.arange(3) # pre, campaign, post
width = 0.35
gold_rates = purchase_rates[purchase_rates['is_gold_member'] == 1]['has_purchase']
regular_rates = purchase_rates[purchase_rates['is_gold_member'] == 0]['has_purchase']
axes[1, 2].bar(x - width/2, gold_rates, width, label='金牌会员')
axes[1, 2].bar(x + width/2, regular_rates, width, label='普通会员')
axes[1, 2].set_xlabel('时期')
axes[1, 2].set_ylabel('购买率')
axes[1, 2].set_title('不同时期购买率对比')
axes[1, 2].set_xticks(x)
axes[1, 2].set_xticklabels(['活动前', '活动期', '活动后'])
axes[1, 2].legend()
plt.tight_layout()
plt.show()
return daily_stats, purchase_rates
# 执行探索性分析
daily_stats, purchase_rates = exploratory_analysis(marketing_clean, user_info)
# 输出关键统计量
print("\n关键统计量:")
print("=" * 50)
pre_campaign = marketing_clean[marketing_clean['period'] == 'pre']
campaign_period = marketing_clean[marketing_clean['period'] == 'campaign']
gold_pre = pre_campaign[pre_campaign['is_gold_member'] == 1]
gold_campaign = campaign_period[campaign_period['is_gold_member'] == 1]
print(f"活动前金牌会员购买率: {gold_pre['has_purchase'].mean():.3f}")
print(f"活动期金牌会员购买率: {gold_campaign['has_purchase'].mean():.3f}")
print(f"名义增长率: {(gold_campaign['has_purchase'].mean() / gold_pre['has_purchase'].mean() - 1) * 100:.1f}%")通过深入的数据探索,我们已经对数据特征和潜在模式有了清晰了解。接下来需要选择适当的因果推断方法来估计活动的真实效果。
在开始建模前,我们需要明确因果关系和识别假设。以下是本次营销活动的因果图:

基于因果图,我们提出以下识别假设:
|
假设 |
内容 |
验证方法 |
|---|---|---|
|
条件独立性 |
给定观察到的用户特征,处理分配与潜在结果独立 |
平衡性检验 |
|
共同支持 |
处理组和对照组的倾向得分分布有重叠 |
倾向得分分布可视化 |
|
平行趋势 |
处理组和对照组在活动前有平行趋势 |
前段趋势检验 |
|
无溢出效应 |
活动效果不溢出到对照组 |
空间相关性检验 |
针对本次评估,我们考虑以下因果推断方法:
# 方法选择评估框架
def method_selection_evaluation(df):
"""评估不同因果推断方法的适用性"""
evaluation_results = {}
# 1. 数据特征分析
n_treated = df[df['is_gold_member'] == 1]['user_id'].nunique()
n_control = df[df['is_gold_member'] == 0]['user_id'].nunique()
evaluation_results['sample_sizes'] = {'treated': n_treated, 'control': n_control}
# 2. 平行趋势检验
pre_period_data = df[df['period'] == 'pre']
trend_comparison = pre_period_data.groupby(['is_gold_member', 'date']).agg({
'purchase_amount_clean': 'mean',
'has_purchase': 'mean'
}).reset_index()
# 计算活动前趋势相关性
gold_trend = trend_comparison[trend_comparison['is_gold_member'] == 1].set_index('date')['purchase_amount_clean']
regular_trend = trend_comparison[trend_comparison['is_gold_member'] == 0].set_index('date')['purchase_amount_clean']
trend_correlation = gold_trend.corr(regular_trend)
evaluation_results['pre_trend_correlation'] = trend_correlation
# 3. 协变量平衡性检查
user_features = df.groupby('user_id').first()[['age', 'income', 'city_tier']]
user_features['is_gold_member'] = df.groupby('user_id')['is_gold_member'].first()
from scipy import stats
balance_results = {}
for feature in ['age', 'income', 'city_tier']:
treated_mean = user_features[user_features['is_gold_member'] == 1][feature].mean()
control_mean = user_features[user_features['is_gold_member'] == 0][feature].mean()
treated_std = user_features[user_features['is_gold_member'] == 1][feature].std()
control_std = user_features[user_features['is_gold_member'] == 0][feature].std()
std_diff = (treated_mean - control_mean) / np.sqrt((treated_std**2 + control_std**2) / 2)
t_stat, p_value = stats.ttest_ind(
user_features[user_features['is_gold_member'] == 1][feature],
user_features[user_features['is_gold_member'] == 0][feature]
)
balance_results[feature] = {
'std_diff': std_diff,
'p_value': p_value,
'balanced': abs(std_diff) < 0.1 and p_value > 0.05
}
evaluation_results['covariate_balance'] = balance_results
# 4. 方法推荐
method_recommendations = []
# 检查DID适用条件
did_appropriate = trend_correlation > 0.8
if did_appropriate:
method_recommendations.append({
'method': 'DID',
'confidence': '高',
'reason': '活动前趋势高度相关,满足平行趋势假设'
})
else:
method_recommendations.append({
'method': 'DID',
'confidence': '中',
'reason': '平行趋势假设需要进一步检验'
})
# 检查PSM适用条件
imbalance_count = sum(1 for feature in balance_results.values() if not feature['balanced'])
if imbalance_count > 0:
method_recommendations.append({
'method': 'PSM',
'confidence': '高',
'reason': f'有{imbalance_count}个协变量不平衡,需要匹配'
})
else:
method_recommendations.append({
'method': 'PSM',
'confidence': '中',
'reason': '协变量基本平衡,PSM仍可提高精度'
})
# 样本量支持多种方法
if n_treated > 1000 and n_control > 1000:
method_recommendations.append({
'method': '多种方法结合',
'confidence': '高',
'reason': '样本量充足,适合方法三角验证'
})
evaluation_results['method_recommendations'] = method_recommendations
return evaluation_results
# 执行方法选择评估
method_evaluation = method_selection_evaluation(marketing_clean)
print("方法选择评估结果:")
print("=" * 50)
print(f"处理组样本量: {method_evaluation['sample_sizes']['treated']}")
print(f"对照组样本量: {method_evaluation['sample_sizes']['control']}")
print(f"活动前趋势相关性: {method_evaluation['pre_trend_correlation']:.3f}")
print("\n协变量平衡性检查:")
for feature, stats in method_evaluation['covariate_balance'].items():
balanced_status = "平衡" if stats['balanced'] else "不平衡"
print(f"{feature}: 标准化差异={stats['std_diff']:.3f}, p值={stats['p_value']:.3f} ({balanced_status})")
print("\n方法推荐:")
for recommendation in method_evaluation['method_recommendations']:
print(f"{recommendation['method']}: 置信度{recommendation['confidence']} - {recommendation['reason']}")基于评估结果,我们决定采用以下分析策略:
主要方法:双重差分法(DID)结合倾向得分匹配(PSM)
辅助方法:合成控制法(作为稳健性检验)
估计目标:平均处理效应(ATE)和异质性处理效应
现在我们已经确定了分析方法,接下来将构建具体的因果模型来估计营销活动的真实效果。
在构建因果模型前,我们需要准备适当的数据格式和特征:
# 数据准备与特征工程
def prepare_causal_analysis_data(df):
"""准备因果分析所需的数据格式"""
# 创建用户级汇总数据
user_level_data = df.groupby('user_id').agg({
'age': 'first',
'income': 'first',
'city_tier': 'first',
'is_gold_member': 'first',
'signup_date': 'first'
}).reset_index()
# 计算活动前行为特征(作为协变量)
pre_period_data = df[df['period'] == 'pre']
pre_behavior = pre_period_data.groupby('user_id').agg({
'purchase_amount_clean': ['sum', 'mean', 'count'],
'has_purchase': 'sum'
}).reset_index()
# 处理多级列名
pre_behavior.columns = ['user_id', 'pre_total_spend', 'pre_avg_spend', 'pre_purchase_count', 'pre_purchase_days']
pre_behavior['pre_purchase_rate'] = pre_behavior['pre_purchase_days'] / len(pre_period_data['date'].unique())
# 计算活动期间结果变量
campaign_data = df[df['period'] == 'campaign']
campaign_behavior = campaign_data.groupby('user_id').agg({
'purchase_amount_clean': 'sum',
'has_purchase': 'sum'
}).reset_index()
campaign_behavior.columns = ['user_id', 'campaign_total_spend', 'campaign_purchase_days']
# 合并所有特征
analysis_data = user_level_data.merge(pre_behavior, on='user_id', how='left')
analysis_data = analysis_data.merge(campaign_behavior, on='user_id', how='left')
# 处理缺失值(新用户可能在某个时期没有行为)
analysis_data = analysis_data.fillna(0)
# 创建时间相关特征
analysis_data['tenure_days'] = (pd.Timestamp('2023-11-01') - analysis_data['signup_date']).dt.days
analysis_data['tenure_group'] = pd.cut(analysis_data['tenure_days'],
bins=[0, 30, 90, 180, 365, float('inf')],
labels=['新用户', '1-3月', '3-6月', '6-12月', '老用户'])
return analysis_data
# 准备分析数据
analysis_df = prepare_causal_analysis_data(marketing_clean)
print(f"分析数据集形状: {analysis_df.shape}")
print(f"金牌会员比例: {analysis_df['is_gold_member'].mean():.3f}")
# 检查处理组和对照组的基线差异
print("\n处理组vs对照组基线特征比较:")
baseline_comparison = analysis_df.groupby('is_gold_member').agg({
'age': 'mean',
'income': 'mean',
'pre_total_spend': 'mean',
'pre_purchase_rate': 'mean',
'tenure_days': 'mean'
}).round(2)
print(baseline_comparison)我们首先使用倾向得分匹配来创建可比较的处理组和对照组:
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
def propensity_score_matching(data, treatment_col='is_gold_member', outcome_col='campaign_total_spend'):
"""实现倾向得分匹配"""
# 准备特征矩阵
feature_cols = ['age', 'income', 'city_tier', 'pre_total_spend', 'pre_purchase_rate', 'tenure_days']
X = data[feature_cols]
T = data[treatment_col]
Y = data[outcome_col]
# 标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 估计倾向得分(使用随机森林)
ps_model = RandomForestClassifier(n_estimators=100, random_state=42)
ps_model.fit(X_scaled, T)
data['propensity_score'] = ps_model.predict_proba(X_scaled)[:, 1]
# 可视化倾向得分分布
plt.figure(figsize=(10, 6))
for treatment_status in [0, 1]:
subset = data[data[treatment_col] == treatment_status]
plt.hist(subset['propensity_score'], alpha=0.7,
label=f"{'处理组' if treatment_status == 1 else '对照组'}",
bins=30, density=True)
plt.xlabel('倾向得分')
plt.ylabel('密度')
plt.title('处理组和对照组的倾向得分分布')
plt.legend()
plt.show()
# 执行最近邻匹配
from sklearn.neighbors import NearestNeighbors
treated = data[data[treatment_col] == 1]
control = data[data[treatment_col] == 0]
# 为每个处理组个体找到最近邻
nbrs = NearestNeighbors(n_neighbors=1, metric='euclidean')
nbrs.fit(control[['propensity_score']])
distances, indices = nbrs.kneighbors(treated[['propensity_score']])
# 应用卡尺(最大距离0.1)
caliper = 0.1
matched_control_indices = []
for i, distance in enumerate(distances):
if distance[0] <= caliper:
matched_control_indices.append(indices[i][0])
matched_control = control.iloc[matched_control_indices]
matched_treated = treated.iloc[[i for i, d in enumerate(distances) if d[0] <= caliper]]
matched_data = pd.concat([matched_treated, matched_control])
print(f"匹配前: 处理组{len(treated)}人, 对照组{len(control)}人")
print(f"匹配后: 处理组{len(matched_treated)}人, 对照组{len(matched_control)}人")
print(f"匹配率: {len(matched_treated) / len(treated):.3f}")
# 检查匹配后平衡性
print("\n匹配后平衡性检查:")
for feature in feature_cols:
treated_mean = matched_treated[feature].mean()
control_mean = matched_control[feature].mean()
treated_std = matched_treated[feature].std()
control_std = matched_control[feature].std()
std_diff = (treated_mean - control_mean) / np.sqrt((treated_std**2 + control_std**2) / 2)
print(f"{feature}: 标准化差异 = {std_diff:.3f}")
return matched_data, matched_treated, matched_control
# 执行倾向得分匹配
matched_data, matched_treated, matched_control = propensity_score_matching(analysis_df)现在实现双重差分模型来估计因果效应:
import statsmodels.api as sm
import statsmodels.formula.api as smf
def difference_in_differences_analysis(matched_data, pre_period_data, campaign_period_data):
"""实现双重差分分析"""
# 准备DID数据
did_data = []
# 处理组:活动前后数据
treated_users = matched_data[matched_data['is_gold_member'] == 1]['user_id']
# 活动前处理组
treated_pre = pre_period_data[pre_period_data['user_id'].isin(treated_users)]
treated_pre_agg = treated_pre.groupby('user_id').agg({
'purchase_amount_clean': 'sum',
'has_purchase': 'sum'
}).reset_index()
treated_pre_agg['period'] = 0 # 0表示活动前
treated_pre_agg['treated'] = 1 # 1表示处理组
# 活动期处理组
treated_campaign = campaign_period_data[campaign_period_data['user_id'].isin(treated_users)]
treated_campaign_agg = treated_campaign.groupby('user_id').agg({
'purchase_amount_clean': 'sum',
'has_purchase': 'sum'
}).reset_index()
treated_campaign_agg['period'] = 1 # 1表示活动期
treated_campaign_agg['treated'] = 1
# 对照组:活动前后数据
control_users = matched_data[matched_data['is_gold_member'] == 0]['user_id']
# 活动前对照组
control_pre = pre_period_data[pre_period_data['user_id'].isin(control_users)]
control_pre_agg = control_pre.groupby('user_id').agg({
'purchase_amount_clean': 'sum',
'has_purchase': 'sum'
}).reset_index()
control_pre_agg['period'] = 0
control_pre_agg['treated'] = 0 # 0表示对照组
# 活动期对照组
control_campaign = campaign_period_data[campaign_period_data['user_id'].isin(control_users)]
control_campaign_agg = control_campaign.groupby('user_id').agg({
'purchase_amount_clean': 'sum',
'has_purchase': 'sum'
}).reset_index()
control_campaign_agg['period'] = 1
control_campaign_agg['treated'] = 0
# 合并所有数据
did_data = pd.concat([treated_pre_agg, treated_campaign_agg, control_pre_agg, control_campaign_agg])
# 创建交互项(DID核心变量)
did_data['post_treatment'] = did_data['period'] * did_data['treated']
# 双重差分回归
model = smf.ols('purchase_amount_clean ~ period + treated + post_treatment', data=did_data).fit()
# 提取DID估计量
did_estimate = model.params['post_treatment']
did_std_err = model.bse['post_treatment']
did_p_value = model.pvalues['post_treatment']
print("双重差分模型结果:")
print(model.summary())
# 可视化DID结果
summary_stats = did_data.groupby(['treated', 'period']).agg({
'purchase_amount_clean': 'mean'
}).reset_index()
plt.figure(figsize=(10, 6))
for treated_status in [0, 1]:
subset = summary_stats[summary_stats['treated'] == treated_status]
label = '处理组' if treated_status == 1 else '对照组'
plt.plot(subset['period'], subset['purchase_amount_clean'], 'o-', label=label, linewidth=2)
plt.axvline(x=0.5, color='red', linestyle='--', alpha=0.7, label='活动开始')
plt.xlabel('时期 (0=活动前, 1=活动期)')
plt.ylabel('平均消费金额')
plt.title('双重差分分析结果')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
return model, did_estimate, did_std_err, did_p_value
# 准备DID所需数据
pre_period_data = marketing_clean[marketing_clean['period'] == 'pre']
campaign_period_data = marketing_clean[marketing_clean['period'] == 'campaign']
# 执行DID分析
did_model, did_estimate, did_std_err, did_p_value = difference_in_differences_analysis(
matched_data, pre_period_data, campaign_period_data
)
print(f"\nDID估计结果:")
print(f"平均处理效应 (ATE): {did_estimate:.2f}")
print(f"标准误: {did_std_err:.2f}")
print(f"p值: {did_p_value:.4f}")
print(f"95%置信区间: [{did_estimate - 1.96 * did_std_err:.2f}, {did_estimate + 1.96 * did_std_err:.2f}]")除了平均效应,我们还关心活动对不同用户群体的异质性效果:
def heterogeneous_effects_analysis(matched_data, marketing_clean):
"""分析处理效应的异质性"""
# 准备用户特征和结果数据
user_features = matched_data[['user_id', 'age', 'income', 'city_tier',
'pre_total_spend', 'pre_purchase_rate', 'tenure_days']]
campaign_results = marketing_clean[marketing_clean['period'] == 'campaign']
campaign_results = campaign_results.groupby('user_id').agg({
'purchase_amount_clean': 'sum'
}).reset_index()
analysis_data = user_features.merge(campaign_results, on='user_id')
analysis_data = analysis_data.merge(matched_data[['user_id', 'is_gold_member']], on='user_id')
# 定义用户细分维度
analysis_data['age_group'] = pd.cut(analysis_data['age'],
bins=[0, 25, 35, 45, 55, 100],
labels=['25以下', '25-35', '35-45', '45-55', '55以上'])
analysis_data['income_group'] = pd.cut(analysis_data['income'],
bins=[0, 5000, 10000, 20000, 50000, float('inf')],
labels=['5k以下', '5k-10k', '10k-20k', '20k-50k', '50k以上'])
analysis_data['value_group'] = pd.qcut(analysis_data['pre_total_spend'], 4,
labels=['低价值', '中低价值', '中高价值', '高价值'])
# 计算各细分的处理效应
hetero_results = []
for dimension in ['age_group', 'income_group', 'value_group']:
for group in analysis_data[dimension].unique():
group_data = analysis_data[analysis_data[dimension] == group]
treated_avg = group_data[group_data['is_gold_member'] == 1]['purchase_amount_clean'].mean()
control_avg = group_data[group_data['is_gold_member'] == 0]['purchase_amount_clean'].mean()
# 简单的差值作为处理效应估计
treatment_effect = treated_avg - control_avg
hetero_results.append({
'dimension': dimension,
'group': group,
'treated_avg': treated_avg,
'control_avg': control_avg,
'treatment_effect': treatment_effect,
'sample_size': len(group_data)
})
hetero_df = pd.DataFrame(hetero_results)
# 可视化异质性效应
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
for i, dimension in enumerate(['age_group', 'income_group', 'value_group']):
dim_data = hetero_df[hetero_df['dimension'] == dimension]
axes[i].bar(range(len(dim_data)), dim_data['treatment_effect'])
axes[i].set_xlabel(dimension)
axes[i].set_ylabel('处理效应')
axes[i].set_title(f'{dimension}的处理效应异质性')
axes[i].set_xticks(range(len(dim_data)))
axes[i].set_xticklabels(dim_data['group'], rotation=45)
# 添加数值标签
for j, effect in enumerate(dim_data['treatment_effect']):
axes[i].text(j, effect + (0.1 if effect >= 0 else -0.5), f'{effect:.1f}',
ha='center', va='bottom' if effect >= 0 else 'top')
plt.tight_layout()
plt.show()
return hetero_df
# 执行异质性分析
hetero_effects = heterogeneous_effects_analysis(matched_data, marketing_clean)
print("异质性效应分析结果:")
print(hetero_effects[['dimension', 'group', 'treatment_effect', 'sample_size']].round(2))通过以上模型构建和分析,我们已经得到了营销活动效果的初步估计。接下来需要进行严格的敏感性分析来验证这些结果的可靠性。
def sensitivity_analysis_psm(matched_data, analysis_df, outcome_col='campaign_total_spend'):
"""对倾向得分匹配结果进行敏感性分析"""
sensitivity_results = {}
# 1. 不同匹配方法的比较
from sklearn.neighbors import NearestNeighbors
def different_matching_methods(data, method='nearest', k=1, caliper=None):
"""实现不同的匹配方法"""
treated = data[data['is_gold_member'] == 1]
control = data[data['is_gold_member'] == 0]
if method == 'nearest':
nbrs = NearestNeighbors(n_neighbors=k, metric='euclidean')
nbrs.fit(control[['propensity_score']])
distances, indices = nbrs.kneighbors(treated[['propensity_score']])
elif method == 'radius':
nbrs = NearestNeighbors(radius=caliper, metric='euclidean')
nbrs.fit(control[['propensity_score']])
distances, indices = nbrs.radius_neighbors(treated[['propensity_score']])
# 应用匹配
matched_control_indices = []
for i, match_indices in enumerate(indices):
if len(match_indices) > 0:
if method == 'nearest':
matched_control_indices.extend(match_indices[:k])
else: # radius matching
matched_control_indices.extend(match_indices)
matched_control = control.iloc[matched_control_indices]
matched_treated = treated.iloc[[i for i in range(len(treated)) if len(indices[i]) > 0]]
return matched_treated, matched_control
# 比较不同匹配方法
methods = [
('1:1最近邻', 'nearest', 1, 0.1),
('1:3最近邻', 'nearest', 3, 0.1),
('半径匹配', 'radius', None, 0.05)
]
method_comparison = []
for method_name, method_type, k, caliper in methods:
matched_treated, matched_control = different_matching_methods(
analysis_df, method_type, k, caliper)
if len(matched_treated) > 0 and len(matched_control) > 0:
treated_avg = matched_treated[outcome_col].mean()
control_avg = matched_control[outcome_col].mean()
ate = treated_avg - control_avg
method_comparison.append({
'method': method_name,
'treated_sample': len(matched_treated),
'control_sample': len(matched_control),
'ate': ate
})
sensitivity_results['matching_methods'] = pd.DataFrame(method_comparison)
# 2. 不同倾向得分模型的比较
def different_ps_models(data, model_type='logistic'):
"""使用不同的模型估计倾向得分"""
feature_cols = ['age', 'income', 'city_tier', 'pre_total_spend', 'pre_purchase_rate', 'tenure_days']
X = data[feature_cols]
T = data['is_gold_member']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
if model_type == 'logistic':
model = LogisticRegression(random_state=42)
elif model_type == 'random_forest':
model = RandomForestClassifier(n_estimators=100, random_state=42)
elif model_type == 'gradient_boosting':
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(n_estimators=100, random_state=42)
model.fit(X_scaled, T)
propensity_scores = model.predict_proba(X_scaled)[:, 1]
return propensity_scores
ps_model_comparison = []
for model_name in ['logistic', 'random_forest', 'gradient_boosting']:
analysis_df_copy = analysis_df.copy()
analysis_df_copy['propensity_score'] = different_ps_models(analysis_df, model_name)





 小程序
企业微信
小程序
企业微信















